Cassandra forma parte del grupo de bases de datos NoSQL orientadas a columnas. Creada inicialmente por Facebook, en 2008 fue liberado como proyecto open source y en febrero de 2010 se convirtió en un proyecto de primer nivel de la fundación Apache.
En una base de datos Cassandra la información se distribuye en grupos de columnas, formadas por una o varias filas, que pueden ser leídas a la vez. Cada grupo de columna, conocido también como familia de columnas, representa la unidad básica de almacenamiento en este tipo de bases de datos.
Características
Entre las principales características de Cassandra destacamos:
Bases de datos distribuidas. La información se puede distribuir a lo largo de una serie de nodos de un cluster. De esta manera se consigue una alta disponibilidad, ya que, si uno de los nodos del cluster se cae, los demás seguirán dando servicio
Escalabilidad horizontal. En una arquitectura de nodos basados en cluster, resulta sencillo añadir nuevos nodos que permitan atender los incrementos de demanda de datos.

Arquitectura peer to peer. Cada nodo está conectado con los demás, esto elimina los puntos de fallo único y permite que cualquiera de los nodos pueda tomar el rol de coordinador.
No dispone de esquema fijo. El número de columnas de una base de datos no es fijo, pudiendo cambiar en tiempo de ejecución.
Componentes de la base de datos
Una base de datos Cassandra es conocida también como espacio de claves y, como ya hemos indicado, se organiza en familias de columnas. A continuación, indicamos los componentes de una base de datos Cassandra y la terminología utilizada:
Espacio de claves. Es el término utilizado para referirnos a una base de datos. Un espacio de claves es una colección ordenada de familia de columnas.
Familia de columna. Es una colección ordenada de columnas. Podríamos asociarlo al concepto clásico de tabla utilizado en las bases de datos relacionales.
Clave de fila. Identificador único de un dato almacenado dentro de una familia de columnas. Asociable a la primary key de las bases de datos relacionales
Columnas. Es la unidad básica del modelo de datos formado por una combinación de clave, valo y timestamp.
SuperColumna. Es una columna cuyos valores son una o más columnas,denominadas subcolumnas, que se encuentran ordenadas.

El lenguaje CQL
Para interaccionar con las bases de datos, Cassandra soporta una versión reducida del lenguaje SQL conocido como Cassandra Query Language (CQL). En Cassandra los datos están desnormalizados de manera que el concepto de joins o subqueries no existe.
Podemos interactuar con Cassandra mediante CQL a través de la shell de CQL, cqlshell. Aunque también es posible utilizar herramientas gráficas que faciliten la interacción, como DevCenter y, por supuesto, existen drivers que permiten crear aplicaciones en diferentes lenguajes (Java, Python, etc.) para el envío de consultas CQL desde una aplicación.
Descarga e instalación
Podemos encontrar la distribución de Cassandra apropiada para nuestro sistema operativo en la dirección:
https://supergsego.com/apache/cassandra
Cassandra se distribuye como un .zip, por lo que simplemente tendremos que descomprimirlo en la carpeta donde queramos tenerla. Eso sí, tenemos que tener en cuenta un par de consideraciones sobre Cassandra antes de intentar ejecutar el servidor de datos:
Soporte de Python 2.7.x. La distribución actual de Cassandra requiere que tengamos instalado Python 2.7.x, si tenemos una versión posterior no funcionará. Podemos tener todas las versiones instaladas de Python que queramos, pero en la variable de entorno Path deberá estar referenciada la carpeta de instalción de Python 2.7
Requiere Java 8. Aunque, dependiendo de la versión de Cassandra descargada, es posible que funcione con Java 7 o incluso Java 10, para asegurarnos deberíamos tener instalado Java 8 y configurar la variable de entorno JAVA_HOME a la carpeta de instalación de esta versión.
Iniciando Cassandra
Una vez instalado, para iniciar Cassandra nos desplazamos a la carpeta bin de instalación y desde la línea de comandos introducimos:
>cassandra
Al cabo de unos segundos veremos que el servidor se ha iniciado y se encuentra escuchando en el puerto 9042. Esta ventana deberá permanecer abierta durante todo el proceso de interacción con el servidor.

Tras iniciar Cassandra, entraremos en el shell de CQL para poder interaccionar con los datos. Para ello, abrimos otra línea de comandos y desde ella introducimos:
>cqlsh
A partir de ahí, ya podemos introducir comandos CQL para interaccionar con el servidor de Cassandra y crear bases de datos, columnas, insertar datos, etc.

Keyspaces
Un Keyspace es el término empleado en Cassandra para referirse a una base de datos. Una vez dentro del shell de cqlsh, si queremos ver la lista de keyspaces existentes utilizamos el comando:
>describe keyspaces
Si lo que queremos es crear un nuevo keyspace, utilizaremos la sentencia create keyspace, seguido del nombre del keyspace. Por ejemplo, para crear un keyspace Empresas sería:
>create keyspace Empresa with replication={‘class’: ‘SimpleStrategy’ ,‘replication_factor’: 3}
El nombre de la estrategia puede ser Simple Strategy o Network Topology Strategy según se vaya usar un único servidor de datos o bien un conjunto de ellos.
El factor de replicación hace referencia al número de réplicas que se van a realizar sobe cada servidor. Para asegurarse que no hay fallos, el mejor valor es 3.
Si lo que queremos es eliminar un keyspace, utilizaremos la sentencia drop keyspace:
>drop keyspace Empresa
Una vez creado el keyspace, podemos entrar en el mismo para manipular su estructura, lo cual haremos a través de la sentencia use:
>use Empresa
Para mostrar la lista de familias de columnas o tablas, usaremos:
>describe tables
Tablas
Una tabla contiene la definición de una familia de columnas. La instrucción CQL para la creación de una tabla en Cassandra es muy similar a SQL:
create table tablename( column1_name datatype PRIMARY KEY, column2_name datatype, column3_name datatype. ) Mediante el modificador primary key se debe indicar la columna clave de la familia. Por ejemplo, si queremos crear una tabla de empleados dentro de la base de datos Empresa, una vez hemos entrado en ella a través de use escribiremos el siguiente comando en el shell:
> create table empleados( dni text primary key, nombre text, edad int )
Como hemos indicado, la estructura de un keyspace es flexible, así pues, si queremos añadir o eliminar columnas a una tabla podemos hacerlo a través de alter table, por ejemplo, para añadir la columna salario a la tabla de ejemplo sería:
> alter table empleados add salario double;
Para eliminar una columna sería:
>alter table empleados drop edad;
Si lo que queremos es eliminar una tabla completa utilizaremos drop table:
>drop table empleados
Operaciones CRUD
El lenguaje CQL dispone de sentencias muy parecidas a SQL para añadir, recuperar, modificar y eliminar datos de una tabla.
Inserción
Para inserción de datos utilizamos insert into:
>insert into empleados (dni,nombre,edad) values(‘3433R’,’pepito’,22)
En caso de existir una fila con el mismo valor de clave, será actualizado con los nuevos valores suministrados.
Recuperación
La recuperación de datos en CQL se realiza mediante la instrucción select. Es muy similar a la select de SQL, si bien en la condición de where se deben incluir columnas primary key o que sean índices, a no ser que añadamos la clausula allow filtering:
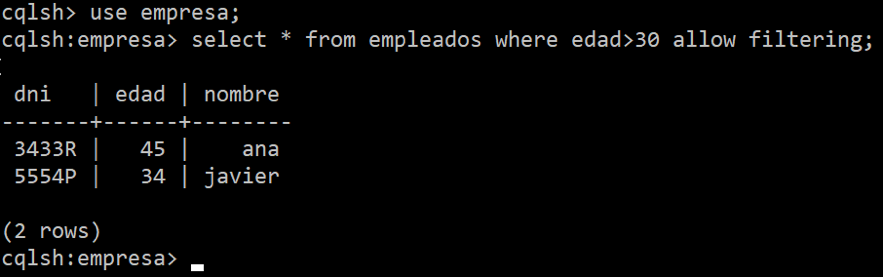
La condición soporta operador and, pero no or.
Eliminación
Para eliminar un conjunto de datos utilizaremos la instrucción delete from. Hay que tener en cuenta que en la condición solo se puede utilizar la primary key:
>delete from empleados where dni=‘da222’;
Podemos eliminar solamente ciertas columnas del conjunto de filas:
>delete edad from empleados where dni=‘da222’;
Actualización
La actualización de datos se realiza mediante la instrucción update. Al igual que delete, la condición de actualización solo puede afectar a la primary key:
update empleados set edad=45 where dni=’3433R’;
Trabajo BBDD Cassandra
En el mismo Jobble podréis ver la cantidad de puestos de trabajo que están solicitando conocimiento de Cassandra
Soluciones Formativas Ofertadas:
Formación Bases de Datos NoSQL
Curso Cassandra Administración
Curso Cassandra Administración & Arquitectura
Curso Cassandra Online
Solicitar Formación In Company